Introduction to Architectures for LLM Applications
In recent years, applications like ChatGPT, Bard, Midjourney, and DALL-E have demonstrated the power of Large Language Models (LLMs) in generating human-like text, images, and content. While these pre-built models provide a magical experience for end users, building custom LLM applications requires a deeper understanding of the architectural choices that power them.
To move from demo applications to production-grade enterprise solutions, product teams, machine learning engineers, and software architects must deal with trade-offs around latency, cost, scalability, and response accuracy. Building an effective LLM application is about more than just calling an API — it’s about controlling the pipeline of data, embeddings, retrieval, and context that feeds into these models.
This article will walk you through the key architectures, tools, and frameworks for LLM applications. You’ll gain a clear understanding of technologies like LangChain, vector databases, and RAG (Retrieval-Augmented Generation). By the end, you’ll have the foundational knowledge to build and deploy custom LLM applications that go beyond simple prompts and responses.
🚀 Why Do We Need Custom Architectures for LLM Applications?
Off-the-shelf solutions like ChatGPT and Bard offer incredible out-of-the-box capabilities. But for more complex use cases, custom architectures are necessary. Here’s why:
Custom Data Needs: Enterprises have proprietary datasets (like customer support logs or internal documents) that general-purpose LLMs can’t access.
Latency and Cost: Calling GPT-4 for every query can get expensive and slow, especially in high-traffic systems.
Consistency and Accuracy: LLMs are prone to hallucinations (incorrect, made-up answers). Custom architectures help ensure consistency and factual accuracy.
Custom Logic and Orchestration: Real-world applications often require multi-step workflows. For example, extracting data from a PDF, processing it, and then answering a user query.
Security and Privacy: For applications in healthcare, finance, or legal, companies cannot send sensitive data to third-party APIs without encryption and security guarantees.
Custom LLM architectures solve these challenges by building pipelines that manage data flow, prompt construction, retrieval, and LLM orchestration.
🔍 Key Components of an LLM Architecture
Here are the essential components required to architect a robust LLM application. Each layer serves a purpose in ensuring accuracy, speed, and scalability.
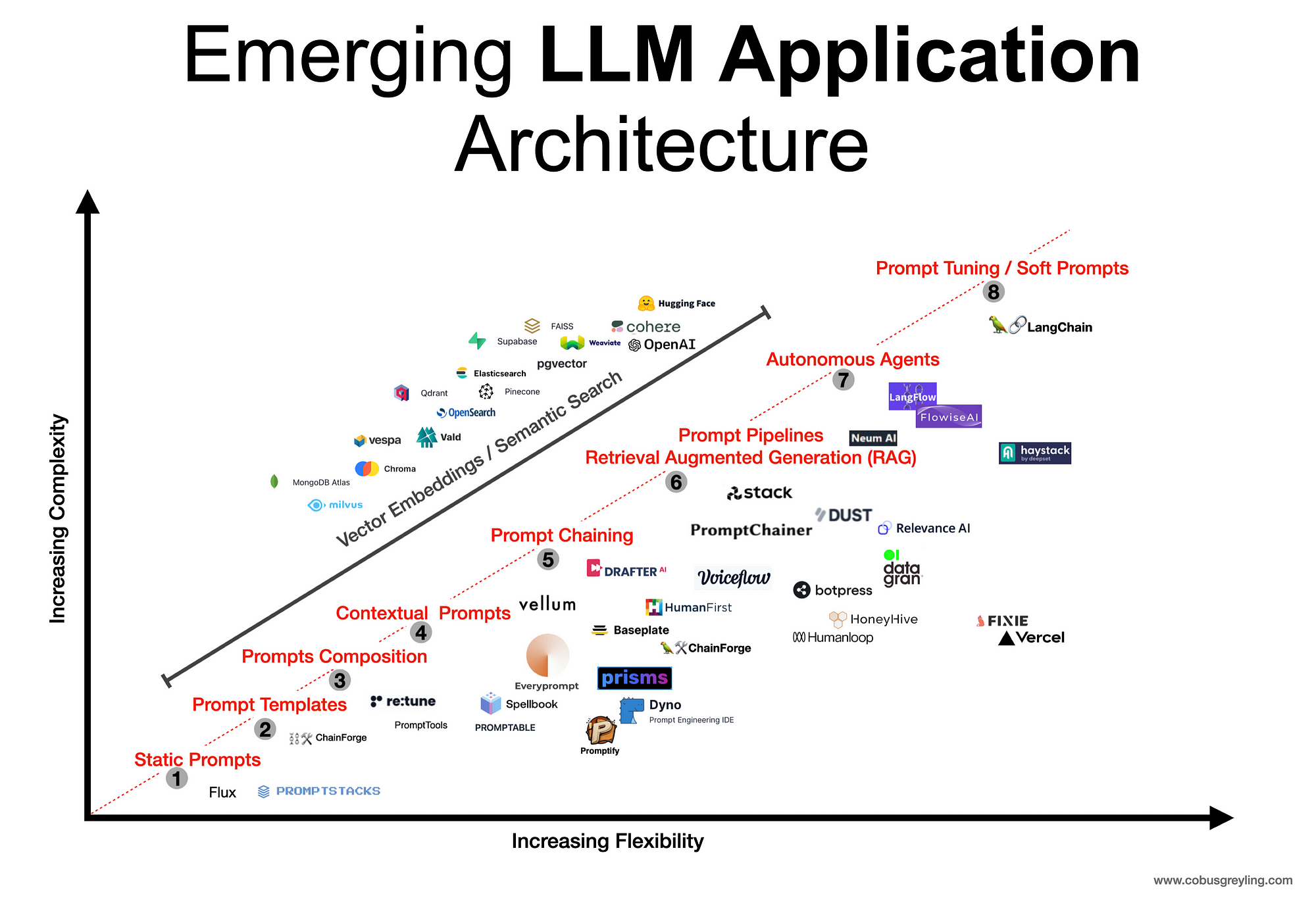
1️⃣ Embeddings and Vector Databases
Purpose: To convert text into machine-readable vectors that can be stored, searched, and retrieved efficiently.
Instead of sending the entire context (like customer support logs) to the LLM, you store the information in a vector database. When a user asks a question, the system retrieves only the relevant context and sends it to the LLM. This reduces token usage and improves latency.
Key Tools:
Vector Databases: Pinecone, Weaviate, Milvus, Qdrant.
Embeddings: OpenAI Embeddings, HuggingFace Transformers, Sentence Transformers.
How It Works:
Split large documents into small chunks.
Use an embedding model to convert each chunk into a vector (dense numerical array).
Store these vectors in a vector database with metadata (like file name, source, etc.).
When a user asks a question, retrieve only the top-k most similar vectors to include as context.
Example Use Case:
A legal AI assistant might need to access past legal documents. Instead of sending all the documents to the LLM, you embed and store them in a vector database. When a user asks about a legal clause, only relevant paragraphs are retrieved and sent to the LLM.
2️⃣ Retrieval-Augmented Generation (RAG)
Purpose: To enable LLMs to retrieve external information and avoid hallucinations.
RAG is a technique where the model "retrieves" information from external knowledge sources (like a database or a document store) before generating a response. This enables models to answer domain-specific questions without relying on LLM pre-training alone.
Key Tools:
LangChain: Helps orchestrate RAG pipelines.
FAISS, Pinecone, Weaviate: Used for fast vector search.
How It Works:
When a user asks a question, the system searches for related context from a vector database.
The retrieved context is combined with the prompt and sent to the LLM.
The LLM generates a response, but now it has better context.
Example Use Case:
A customer service chatbot might need to provide answers from a product knowledge base. Instead of relying solely on LLM training, the system retrieves product-specific documentation and appends it to the LLM prompt.
Example Query: "How do I update the firmware on Model X1000?"
The system retrieves relevant content from the Product Manual PDF stored in a vector database.
The context is appended to the prompt, and the LLM generates a precise response.
3️⃣ Prompt Engineering and Orchestration
Purpose: To control and optimize how LLMs are "prompted" to produce better results.
Prompt engineering defines what you ask the LLM and how the input is formatted. Orchestration goes one step further by managing multi-step workflows.
Key Tools:
LangChain: For multi-step LLM workflows and prompts.
Prompt Templates: Pre-built templates for common use cases.
How It Works:
Templates are created for specific use cases (e.g., "Summarize this document" or "Extract entities").
Multi-step workflows are designed, such as "query API → extract result → send to LLM".
Orchestration frameworks like LangChain manage these steps.
Example Use Case:
A financial assistant that generates reports might require a multi-step orchestration. First, the assistant queries a stock API, formats the result, and finally asks the LLM to summarize the result into a user-friendly summary.
4️⃣ Data Privacy and Security
Purpose: To prevent sensitive information from being leaked to third-party APIs.
When building healthcare, finance, or legal LLM applications, data security is paramount. Companies must protect PII (Personally Identifiable Information) and ensure compliance with GDPR, HIPAA, and other privacy regulations.
Key Tools:
On-Prem Models: Use local LLMs (LLaMA, Dolly) instead of sending data to OpenAI's API.
Data Masking: Remove sensitive information before sending to the LLM.
Encrypted Requests: Secure data in transit using TLS/SSL.
5️⃣ Caching and Rate-Limiting
Purpose: To reduce API costs, improve response time, and avoid overloading LLM providers.
Key Tools:
Redis or Memcached: Cache frequent responses.
Rate Limiting: Prevent excessive API calls.
How It Works:
Cache frequent queries so that if users ask the same question, the system returns the cached response.
Apply rate limiting to ensure the system doesn’t exceed API quotas.
📘 LLM Architecture Overview
Here’s what a modern LLM architecture might look like:
scssCopy code
1. User Query → 2. Orchestration (LangChain) → 3. Embedding and Retrieval (FAISS) → 4. Contextual Prompt → 5. LLM Call (like OpenAI API) → 6. Response
Key Concepts:
Data Ingestion: PDF files, API responses, and logs are ingested.
Data Embedding: Convert text into vectors using embeddings.
Retrieval (RAG): Pull relevant context from vector databases.
Prompt Orchestration: Format context + user query into a final LLM prompt.
🛠️ Key Tools for LLM Development
ToolUse CaseLangChainPrompt templates, multi-step workflowsWeaviate, PineconeVector search and retrievalFAISSLocal vector searchOpenAI APIAccess to LLMs like GPT-4RedisResponse caching and rate limiting
🎉 Final Thoughts
Custom LLM applications go beyond calling an API. You need to understand embeddings, vector search, retrieval-augmented generation (RAG), and orchestration workflows. Tools like LangChain, Weaviate, and FAISS simplify this process.
Building a custom LLM application is no longer about "trying out ChatGPT." It’s about optimizing architecture for speed, cost, and accuracy. With the right framework, you can develop smarter, faster, and more reliable AI systems tailored to your specific needs.
Call to Action: Ready to start building? Start with LangChain to orchestrate your workflows, use vector databases to manage context, and ensure privacy and security for sensitive data.